1. はじめに
1.1 記事の目的と想定読者
Cortex Analystは、自然言語で入力された質問を自動的にSQLに変換して、データを抽出するText to SQLのサービスです。
本記事では、Cortex Analystを初見でもこの記事を見れば、実装まで持っていけるように解説していきます。
想定読者は、以下のような課題をお持ちの方です。
- Snowflake を導入済み、あるいは導入を検討していて、Text to SQL を用いたサービスを取り入れたい企業担当者
- レポート作成やデータ抽出依頼に追われていて、依頼対応のためのSQLを書く時間を減らしたいデータ担当者
- 「Cortex Analyst って聞いたことあるけれど、なんなのそれ?」と疑問をお持ちの方
こうした方々が、Cortex Analystを活用してどのように効率化を図れるのか、本記事で理解し、導入の検討材料としてお使いいただけるようになっていますので、ぜひ最後まで読んでいただけますと幸いです!
1.2 Snowflake Cortex Analyst とは?
Cortex Analyst は、LLMを用いてユーザーから受け取った自然言語での質問から SQL クエリを出力する、Text to SQL 機能を持つサービスです。REST API で提供されるため、なんとSlackでも使う事ができます!
これを使うと、Snowflake 内にあるデータを自然言語で問いかけるだけで分析できるようになります。
1.3 記事の概要
本記事では、賃貸データを例に取り上げながら、Cortex Analyst でどんな分析ができるのかStreamlit in Snowflake上でのデモ紹介を交えて解説します。
Cortex Analyst の特徴や実装例、運用コストの観点まで順に説明していきます。
2. Cortex Analyst の特徴
| 機能 | 概要 |
|---|---|
| Text to SQL | ユーザーからの自然言語での問い合わせを SQL クエリに自動変換できます。 これにより、ユーザーはSnowflakeからデータを抽出する際にSQLを書く必要がありません。 |
| セマンティックモデル | テーブル構造やカラム情報をセマンティックモデル(ymal)で定義し、LLMがビジネス要件に沿ったSQLを生成できるようサポートをする役割です。 |
| REST API提供 | Slack、Teams、Streamlitなど多様なツールと容易に統合可能です。 様々な環境からCortex Analystを利用できるようになります。 |
3. デモ紹介
4. アーキテクチャとシステム構成
4.1 全体構成図とデータフロー
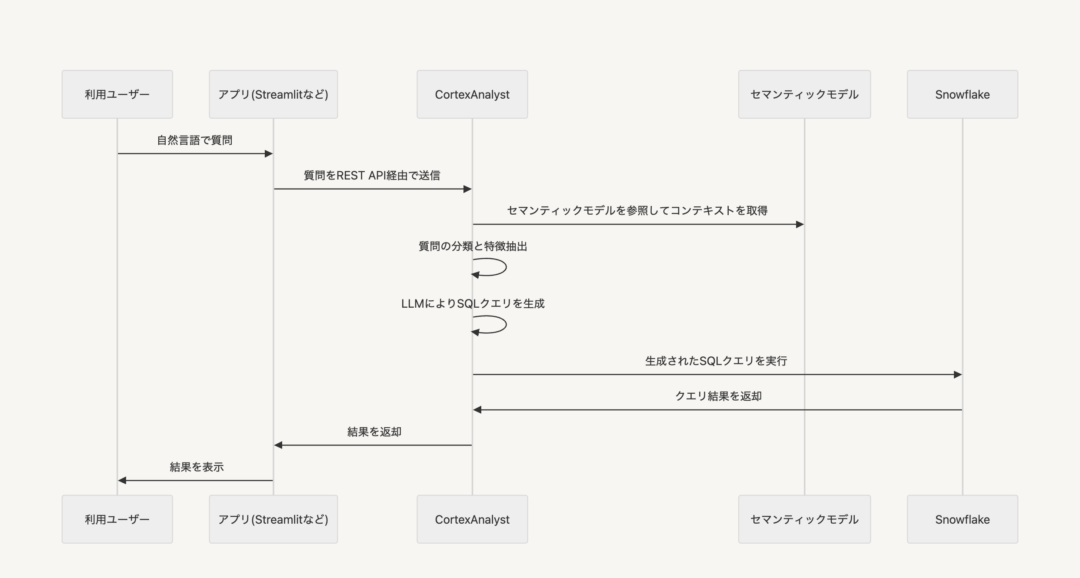
4.2 REST API 連携の仕組み
4.2.1 Request body
フィールド構成
| フィールド名 | 必須 | 型・例 | 説明 |
|---|---|---|---|
| messages | 必須 | 配列 | ユーザーの質問および会話履歴を格納する配列。 |
| ┗ role | 必須 | “user” | メッセージを送信した役割を指定 (現在はuserのみサポート)。 |
| ┗ content | 必須 | オブジェクトの配列 (例: [{“type”:”text”,”text”:”県別の平均家賃を教えてください”}]) | メッセージの詳細情報。 |
| ┗ ┗ type | 必須 | “text” | コンテンツのタイプ (テキストのみサポート)。 |
| ┗ ┗ text | 必須 | “県別の平均家賃を教えてください” | ユーザーの自然言語による質問。 |
| semantic_model_file | いずれか | @my_stage/my_semantic_model.yaml | セマンティックモデルファイルへのパスを指定。 |
| semantic_model | いずれか | “<YAML_CONTENTS>” | セマンティックモデルのYAML内容を直接文字列として指定。 |
注: semantic_model_file または semantic_model のどちらかは必ず指定してください。
リクエストボディ例
{ "messages": [ { "role": "user", "content": [ { "type": "text", "text": "県別の平均家賃を教えてください" } ] } ], "semantic_model_file": "@{データベース名}/{スキーマ名}/{ステージ名}/{セマンティックモデル名.ymal}" } 4.2.2 Response
レスポンス構造
レスポンスは、会話の履歴が messages 配列として返されます。
アナリスト側の回答には role が “analyst” となり、content の type に応じて以下の情報が含まれます。
| フィールド | 値 | 説明 |
|---|---|---|
| role | “user” or “analyst” | メッセージの作成者 (ユーザー、またはアナリスト) |
| content | 配列 | メッセージの実際の内容(テキストやSQL)が格納される。 |
| ┗ type | “text” / “sql” / “suggestion” | メッセージの種類を示す • text: テキストの回答 • sql: 生成されたSQLクエリ • suggestion: 質問が曖昧な場合の提案 |
| ┗ text (または statement) | 文字列 | 実際のテキスト、またはSQL文が格納される。 |
レスポンス例
- role: “analyst” のメッセージに含まれる type: “sql” のコンテンツが、生成されたSQLクエリとなります。
- type: “suggestion” が返される場合は、ユーザーの質問が曖昧なためにSQLを生成できなかったことを示唆します。
{ "messages": [ { "role": "user", "content": [ { "type": "text", "text": "県別の平均家賃を教えてください" } ] }, { "role": "analyst", "content": [ { "type": "text", "text": "This is our interpretation of your question:" }, { "type": "sql", "statement": "SELECT prefecture, AVG(rent_price) FROM rent_list ORDER BY rent_price;" } ] } ] } 5. 導入手順と実装フロー
5.1 セマンティックモデルの作成・ステージへの格納
セマンティックモデルの説明
セマンティックモデルは、以下の要素で構成されます。
セマンティックモデル名
セマンティックモデルに登録するテーブルたちの総称をつける
テーブル
セマンティックモデルに登録したいテーブルを記載する
┗
ディメンション(Dimentions)
データの属性や特性を表すカラム
例) 物件の住所、都道府県、建物の種類など
時間ディメンション(Time Dimensions)
日付や日時など、時間に関連するカラム
例) 建築年、改築年
メジャー (Measure)
数値的な集計値を表すカラム
例) 家賃など。AVG、SUMやCOUNTなどのよくされる集計のされ方を定義できる
検証済みクエリ(verified_queries)
想定される質問と、その質問に対するSQLを記載しておくことで、Cortex Analystの回答精度を上げることができる
セマンティックモデルの構築
- セマンティックモデル名の設定
# 複数ファイルを記載する際はそれを統括する名称を記載する name: rent_sample_list description: 賃貸物件の家賃や所在地、建物状態などを含むデータ2. CortexAnalystに読み込ませるテーブルの設定
- name:セマンティックレイヤー上でのテーブルの名称を指定
- description:テーブルの内容の説明
- base_table:実際にSnowflake内に格納されているテーブルを指定
tables: - name: rent_sample_list description: 賃貸物件の家賃や所在地、建物状態などを含むデータ base_table: database: DATA_LAKE schema: REAL_ESTATE table: RENT_SAMPLE_LIST3. 設定したテーブルのカラムの設定
各テーブル内のカラムを以下のように分類し、設定する
- time_dimensions:時間に関連するディメンションを定義
- measures:集計に使用する値を定義各項目で設定する主な属性は以下になります。
- name:項目の名称を指定
- synonyms:同義語をリスト形式で指定
- description:カラムの説明を記載
- expr:Snowflakeに格納されているカラムを記載
- data_type:データ型を指定 (例:STRING, NUMBER, DATE)
- unique:値が一意であるかどうかを指定 (true or false)
- default_aggregation:メジャーの場合、デフォルトの集計方法を指定SUM:合計
- AVG:平均値
- MIN:最小値
- MAX:最大値
- COUNT:値の総数
- COUNT_DISTINCT:重複しない値の総数
dimensions: - name: adress synonyms: ["住所", "所在地"] description: "賃貸の住所" expr: ADRESS data_type: STRING unique: true time_dimensions: - name: building_year description: 建築年 synonyms: ["建物の建築年", "建物の築年"] expr: BUILDING_YEAR data_type: DATE measures: - name: rent_price description: 賃貸価格 synonyms: ["家賃", "賃料"] expr: RENT_PRICE data_type: number # デフォルトの集計方法 default_aggregation: AVG4. (任意)テーブル同士のつながりの設定
こちらを設定することで、必要があれば複数のテーブルから参照して、SQLを記載してくれるように設定可能
- relationships:複数のテーブル間のリレーションシップを定義
- name:リレーションシップの一意の名称を指定
- description:リレーションシップの概要や目的を説明
- primary_table:結合の主側となるテーブルの名称を指定
- foreign_table:結合の従側となるテーブルの名称を指定
- primary_key:主テーブル内のキーとなるカラムを指定
- foreign_key:外部テーブル内で主キーに対応するカラムを指定
- relationship_type:テーブル間の結合の種類を指定。
主な選択肢は以下の通りです。- one_to_one:1対1
- one_to_many:1対多
- many_to_one:多対1の
- many_to_many:多対多
- join_type:SQL クエリで使用される結合の種類を指定
主な選択肢は以下の通りです。- inner:両方のテーブルに共通するデータのみを取得
- left_outer:主テーブルの全データと、条件に一致する外部テーブルのデータを取得
- right_outer:外部テーブルの全データと、条件に一致する主テーブルのデータを取得
- full_outer:両方のテーブルの全データを取得
relationships: - name: rent_list_product_relationship description: "賃貸リストテーブルとユーザーの賃貸閲覧情報のリレーションシップ" join_type: left_outor primary_table: rent_list foreign_table: user_log primary_key: adress foreign_key: adress5. 想定される質問とそれに対するSQLの記載
verified_queries: - name: average_rent_price question: 県毎の家賃の平均を教えてください。 sql: | SELECT prefecture, AVG(RENT_PRICE) AS average_rent_price FROM DATA_LAKE.REAL_ESTATE.RENT_SAMPLE_LIST GROUP BY prefecture; - name: tokyo_rent_less_than_100000_floor_more_than_2 question: 東京都で、家賃が10万円以上で、階数が2階以下の物件の住所と家賃を教えてください sql: | SELECT adress, rent_price FROM DATA_LAKE_AOKI.REAL_ESTATE.RENT_SAMPLE_LIST WHERE prefecture = '東京都' AND rent >= 100000 AND floor <= 2;格納したいスキーマへのステージの格納
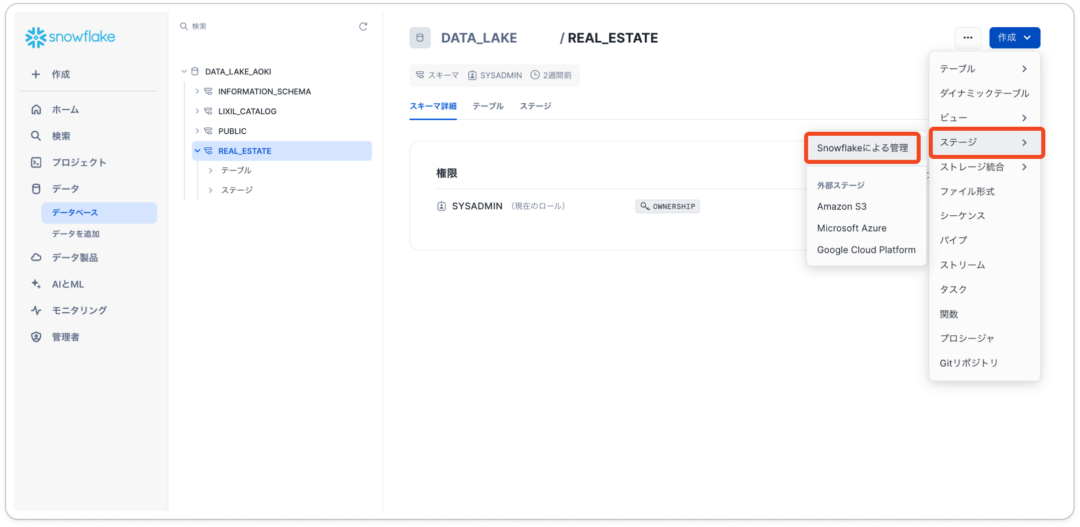
- 「データベース」タブへ移動し、ステージからSnowflakeによる管理をクリック
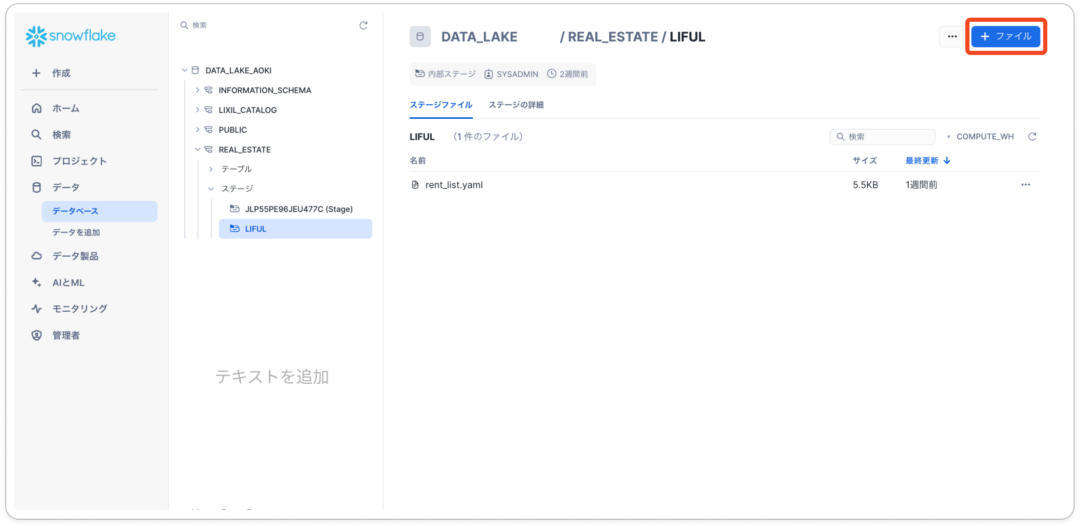
2. ステージを作成したら、そこのステージからセマンティックレイヤーを記載したymalファイルを格納する
5.2 Cortex Analystを用いたコードの作成
実運用で活用する際は、グローバル変数で記載するステージの場所を、実際にご自身の環境に合わせて変更してください。
以下に示したコードは、公式ドキュメントのチュートリアル部分を参考に構築したサンプルです↓
importjsonimportstreamlitasstfromsnowflake.snowpark.contextimportget_active_sessionfromstreamlit.errorsimportStreamlitAPIExceptionimport_snowflakeDATABASE = "DATA_LAKE_AOKI"SCHEMA = "REAL_ESTATE"STAGE = "LIFUL"FILE = "rent_list.yaml"defbuild_request_body(prompt: str) -> dict:messages = [{ "role": "user", "content": [ {"type": "text", "text": prompt} ] } ]body = { "messages": messages, "semantic_model_file": f"@{DATABASE}.{SCHEMA}.{STAGE}/{FILE}", }returnbodydefcall_cortex_api(request_body: dict) -> dict:response = _snowflake.send_snow_api_request("POST", # method"/api/v2/cortex/analyst/message", # url{}, # headers{}, # cookiesrequest_body, # body{}, # files 30000 # timeout )returnresponsedefparse_cortex_response(response: dict) -> dict:ifresponse["status"] dict:body = build_request_body(prompt)raw_response = call_cortex_api(body)returnparse_cortex_response(raw_response)defdisplay_text_item(item: dict) -> None:""" メッセージがtextの場合、Streamlit上に表示する。""" st.markdown(item["text"])defdisplay_suggestions_item(item: dict,message_index: int) -> None:withst.expander("Suggestions",expanded=True):forsuggestion_index,suggestioninenumerate(item["suggestions"]):ifst.button(suggestion,key=f"{message_index}_{suggestion_index}"):st.session_state.active_suggestion = suggestiondefdisplay_sql_item(item: dict) -> None: # SQL文を折りたたみ表示withst.expander("SQL Query",expanded=False):st.code(item["statement"],language="sql") # 実行結果を表示withst.expander("Results",expanded=True):withst.spinner("Running SQL..."):try:session = get_active_session()df = session.sql(item["statement"]).to_pandas()iflen(df.index) > 1:data_tab,line_tab,bar_tab = st.tabs(["Data","Line Chart","Bar Chart"])data_tab.dataframe(df)iflen(df.columns) > 1:df = df.set_index(df.columns[0])withline_tab:st.line_chart(df)withbar_tab:st.bar_chart(df)else:st.dataframe(df)exceptStreamlitAPIExceptionase:st.warning('⚠️ グラフ機能を作成するには、数値カラムとディメンションカラムを1つずつ含む必要があります。')exceptExceptionase:st.error(f"エラーが発生しました: {e}")defdisplay_content(content: list,message_index: int = None) -> None:ifmessage_indexisNone:message_index = len(st.session_state.messages)foritemincontent:item_type = item["type"]ifitem_type == "text":display_text_item(item)elifitem_type == "suggestions":display_suggestions_item(item,message_index)elifitem_type == "sql":display_sql_item(item)defprocess_user_input(prompt: str) -> None: # ユーザーメッセージをチャット履歴に保存st.session_state.messages.append({"role": "user", "content": [{"type": "text", "text": prompt}]} ) # ユーザーの入力を画面に表示withst.chat_message("user"):st.markdown(prompt) # アシスタントからの応答を取得・表示withst.chat_message("assistant"):withst.spinner("Generating response..."):response_dict = fetch_cortex_response(prompt)content = response_dict["message"]["content"]display_content(content=content) # アシスタントの応答をチャット履歴に保存st.session_state.messages.append({"role": "assistant", "content": content} )defmain():st.title("Cortex Analyst")st.markdown(f"Semantic Model: `{FILE}`") # セッション変数の初期化if"messages"notinst.session_state:st.session_state.messages = []if"active_suggestion"notinst.session_state:st.session_state.active_suggestion = None # 既存メッセージの表示foridx,messageinenumerate(st.session_state.messages):withst.chat_message(message["role"]):display_content(content=message["content"],message_index=idx) # ユーザー入力を受付ifuser_input := st.chat_input("質問を入力してください"):process_user_input(prompt=user_input) # サジェストがクリックされている場合ifst.session_state.active_suggestion:process_user_input(prompt=st.session_state.active_suggestion)st.session_state.active_suggestion = Noneif__name__ == "__main__":main()5.3 Streamlit in Snowflake での設定
Streamlit in Snowflake を利用する場合、Snowflake のワークシートやUI上で下記のようにアプリをセットアップします。
- Snowsight上にて、「Streamlit」のタブへ移動
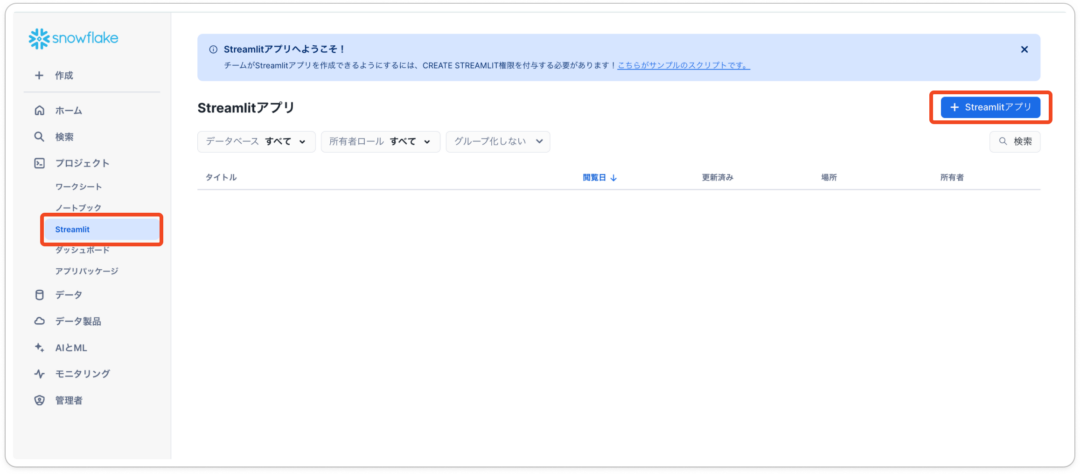
2. 「Streamlitアプリ」をクリックし、以下の項目を設定
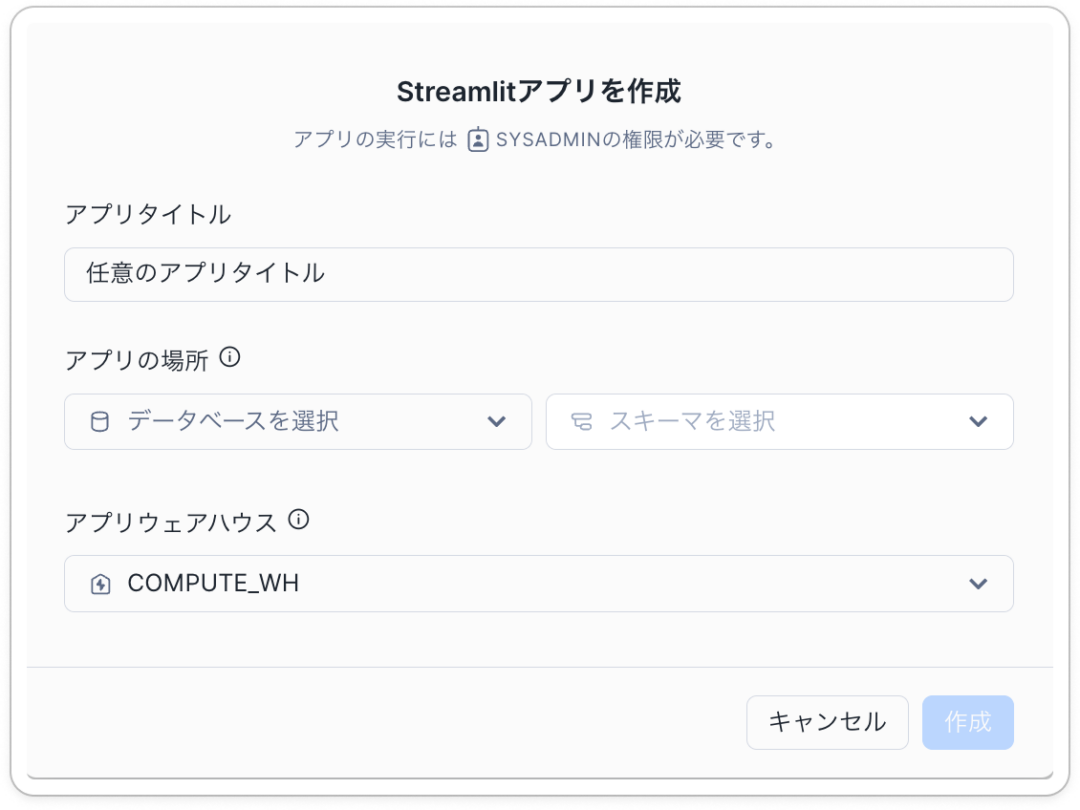
3. 設定が完了したら、書き換えたコードをこちらに貼り付け、動作を確認する
6. 料金体系とコスト試算
Cortex Analystの利用料金は、メッセージリクエスト数に応じて計算されます。 1,000メッセージあたり 67クレジット が消費される料金体系です。
Snowflakeのクレジット単価はエディションや契約内容、リージョンによって異なります。正確な単価や料金計算については、以下の公式ドキュメントや営業担当者にお問い合わせください。
7. おわりに
実際にCortex Analystに触れてみて思ったのは、こんなに簡単かつ早く自然言語でリクエストしたものがSQLになって帰ってくるんだという衝撃を受けました。
様々な組織で昨今のDXブームもあってデータだけ蓄積していて、それをうまく扱えていなかったり、分析者不足でビジネスサイドでも使いたくても使えないなんてことがあったところも多いと思っています。
そんな中で、データ管理者が不在のMTGなどで、一瞬で、「この3か月の地域別売り上げトップはどこ?」とSlackなどに搭載されたCortex Analystで質問するだけで、その場でSQLクエリが生成され、結果を即座に返してくれます。
従来ならデータ担当者に依頼して結果を待つ必要がありましたが、その手間が省けるため、会議中に実際の数値をもとに意思決定ができるようになったりします。
データ担当者の視点でも、細かなデータ抽出に時間を取られず、本来の分析やモデル構築といったコア業務に集中できる点が大きなメリットです。
さらに、セマンティックモデルをしっかり作り込んでおけば、少し難易度が高かったり、複雑なクエリでも作成して、抽出してくれたり、曖昧な質問でも精度の高いSQLクエリを生成できるため、ビジネスユーザーが直感的にデータを活用する環境を整えやすいと感じました。実際に触れてみると、集計や比較といったリクエストは非常にスムーズに処理されます。
こうした手軽さは、社内のデータ活用を一気に加速する切り札になり得ると思いますし、これまであまりデータに触れていなかった層にも、幅広くリーチできるサービスだと思ったので、ぜひ皆さんもご活用ください!
Appendix
公式ドキュメント
Cortex Analyst | Snowflake Documentation